Type de données
Les éléments d'un tableau multidimensionnel doivent tous être du même type. Il y a quatre types de données de base qui sont les booléens et les nombres entiers, flottants et complexes.
Quand on crée un tableau, le type de données de ses éléments est choisi selon le contexte. Pour connaitre ce type, on peut consulter l'attribut dtype des objets ndarray. Voyons quelques exemples avec différentes techniques de création de tableau vues précédemment :
Lorsque l'on crée un tableau en fournissant directement les données à y stocker (avec array, full ou arange), elles prennent le type des valeurs d'initialisation, à savoir des nombres entiers dans notre exemple (plus précisément, il s'agit du type de données int64, car la machine sur laquelle le code a été exécuté est une machine $64$ bits). Les fonctions zeros, ones et linspace produisent, quant à elles, des tableaux dont les valeurs sont des nombres flottants :
int64 float64 float64 int64 int64 float64
L'exemple suivant fait en sorte que les données des tableaux qui étaient précédemment de type int64 soient maintenant de type float64 :
Dans le premier cas, il suffit qu'une seule des valeurs de la liste soit un nombre flottant. Dans le deuxième cas, on fournit directement un nombre flottant comme valeur d'initialisation. Enfin, dans le dernier cas, on utilise un nombre flottant comme pas d'incrément. Le résultat de l'exécution confirme que l'on a bien des tableaux de float64 :
float64 float64 float64
Définir le type
Les types de données sont définis par une série de classes, toutes descendantes de la classe dtype de NumPy. Le type d'un tableau définit quelles sont les valeurs qu'il est possible d'y stocker et aussi l'espace occupé en mémoire pour chaque élément du tableau.
Les quatre types de base sont représentés par les classes bool_, int_, float_ et complex_. On peut utiliser ces classes pour transformer une donnée ou une liste Python en un ndarray dont les éléments auront le type correspondant. Voici, par exemple, comment créer un tableau dont les éléments sont des nombres complexes :
La liste Python, constituée de nombres entiers, va être transformée en un ndarray de nombres complexes, comme on peut le constater sur le résultat de l'exécution :
[ 7.+0.j -1.+0.j 2.+0.j]
Une autre façon de procéder pour spécifier le type désiré lors de la création d'un ndarray consiste à utiliser le paramètre optionnel dtype lors de sa création. Voici, par exemple, comment créer un ndarray de nombres flottants, à partir de nombres entiers :
Contrairement à ce que l'on a vu précédemment, où la fonction arange créait un tableau de nombres entiers par défaut, on constate ici que l'on a bel et bien des nombres flottants :
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
Espace mémoire
Lorsque l'on utilise les quatre types de base, on n'a pas vraiment de contrôle sur l'espace mémoire occupé par un tableau. On peut connaitre cette quantité de mémoire avec l'attribut itemsize des ndarray. Ce dernier contient le nombre d'octets occupés par chaque élément du tableau. Cette quantité est, pour rappel, identique pour tous les éléments d'un même tableau, puisque ces derniers sont homogènes.
Un élément de type bool_ occupe toujours un octet en mémoire. Pour les trois autres types, à savoir int_, float_ et complex_, cela peut varier selon la machine. Si on veut un contrôle précis sur l'espace mémoire, on peut utiliser des types spécifiques, comme float16, float32 et float64 pour les nombres flottants, par exemple.
Le programme suivant compare l'espace mémoire occupé par les différents types pour les nombres flottants :
On remarque que, sur cette machine, le type float_ est un raccourci pour float64, les données de ce type occupant huit octets ($64$ bits) :
8 2 4 8
Pour rappel, un tableau multidimensionnel NumPy est stocké dans des blocs mémoire consécutifs. Plus précisément, on se retrouve avec une organisation structurée par dimensions. La mémoire est tout d'abord découpée en blocs de même taille, en fonction du nombre d'éléments dans le premier axe. Chacun de ces blocs est ensuite lui-même découpé en sous-blocs en fonction du nombre d'éléments du deuxième axe. La découpe continue ainsi de suite pour toutes les dimensions du tableau.
Pour mieux comprendre cette organisation en mémoire, prenons l'exemple suivant qui crée un tableau à trois dimensions :
Comme on le voit sur le résultat de l'exécution, il s'agit d'un tableau de dimensions $(3, 2, 3)$ dont chaque élément occupe $1$ octet ($8$ bits) en mémoire. En effet, grâce au paramètre optionnel dtype, on a forcé l'utilisation du type np.int8. En tout, il faut donc $18$ octets pour stocker tous les éléments du tableau (on a en effet un total de $3 \times 2 \times 3 = 18$ éléments $\times 1$ octet $= 18$ octets), ce qu'on confirme en affichant la valeur de l'attribut nbytes du tableau qui contient l'espace total occupé en mémoire par le tableau, en octets :
[[[ 1 2 3] [ 4 5 6]] [[ 7 8 9] [10 11 12]] [[13 14 15] [16 17 18]]] (3, 2, 3) 1 18
La figure 3 montre l'organisation en mémoire de ce tableau. La première dimension possède trois éléments et les $18$ octets sont donc découpés en trois blocs de $6$ octets (D1). Chacun de ces blocs est ensuite lui-même découpé en deux blocs puisque la deuxième dimension possède deux éléments. Chaque bloc de deuxième niveau de $6$ octets est donc découpé en deux blocs de $3$ octets (D2). Enfin, au troisième niveau, on a une dernière découpe de chaque bloc de deuxième niveau de $3$ octets en trois blocs de $1$ octet chacun, puisque la troisième dimension possède trois éléments (D3). Comme détaillé à la section suivante, cette organisation permet un accès efficace aux éléments du tableau.
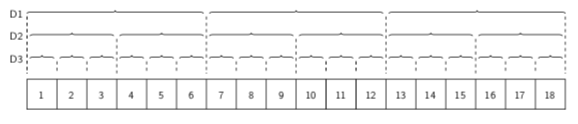
On peut connaitre la taille des blocs mémoire pour chacune des dimensions, en octets, en consultant l'attribut strides des ndarray :
Le résultat de l'exécution confirme ce qu'on a déjà pu calculer plus haut. Un bloc en première dimension occupe $6$ octets, un bloc en deuxième dimension $3$ octets et enfin, les derniers blocs, ceux de la troisième dimension, occupent $1$ octet en mémoire :
(6, 3, 1)
Précision de arange versus linspace
Enfin, pour terminer cette section, voyons un effet pervers qui peut se produire lorsque l'on crée des tableaux en ne faisant pas attention au type de données utilisé. Ce type peut, en effet, avoir un impact sur le choix de la méthode de création à utiliser. En effet, le calcul en nombres flottants est moins précis que celui en nombres entiers, tous les nombres réels n'étant pas représentables avec des float_.
Une situation qui pourrait être non désirable est le fait qu'il n'est pas forcément possible de prédire le nombre d'éléments d'un ndarray créé avec la fonction arange, si elle est utilisée avec des paramètres flottants. Si on veut des garanties sur ce nombre d'éléments, il est conseillé d'utiliser la fonction linspace.
L'exemple suivant illustre ce problème, en tentant de créer des tableaux de nombres flottants, séparés par un pas d'incrément de 0,2 :
Le premier tableau devrait avoir deux éléments (1 et 1,2) comme l'élément de fin est exclu avec la fonction arange, pour rappel. La deuxième instruction devrait, quant à elle, créer un tableau contenant trois éléments (1, 1,2 et 1,4). Enfin, le tableau créé par la dernière instruction devrait avoir quatre éléments (1, 1,2, 1,4 et 1,6). Comme le montre le résultat de l'exécution, on n'a pas le résultat attendu pour le deuxième tableau créé, l'élément de fin faisant partie du tableau :
[1. 1.2] [1. 1.2 1.4 1.6] [1. 1.2 1.4 1.6]
Pour éviter ce problème, une solution consiste à utiliser la fonction linspace. Voici un code alternatif, mais qui produit le résultat désiré :