Caractère
En typographie, un caractère est une pièce que l'on tapisse d'encre pour ensuite la presser sur un support comme une feuille de papier, dans le but d'y laisser son empreinte. La figure 1 montre le caractère « fi ».

La partie supérieure de la pièce est en relief et contient le glyphe d'un caractère, c'est-à-dire une représentation graphique de ce dernier. Une fonte de caractères correspond à l'ensemble de tous les caractères mobiles de même corps (taille), graisse et style (romain, italique, ombré, etc.) pour une police donnée. Une police d'écriture fait l'inventaire des fontes de caractères, regroupant tous les corps et graisses d'une même famille. Par exemple, « Garamond » est une police d'écriture alors que « Garamond romain gras 12 points » est une fonte de caractère.
Depuis l'apparition de l'informatique, on confond souvent fonte et police. En effet, puisque le stockage des caractères est maintenant fait sous forme numérique, il est possible de les redimensionner. Il ne faut donc plus stocker toutes les tailles différentes comme c'était le cas lorsqu'on utilisait les caractères en plomb. On peut également, dans une certaine mesure, calculer des graisses et styles différents.
Caractère informatique
En informatique, un caractère est un type de donnée, mais également une notion abstraite. On retrouve évidemment tous ceux utilisés en typographie tels que les lettres minuscules et majuscules, les chiffres et les signes de ponctuation. De plus, on retrouve des caractères de contrôle, qui ne représentent pas un symbole, tels que les espaces, les tabulations, les retours à la ligne, etc.
La représentation abstraite des caractères sous forme numérique est récente et a notamment été développée pour le télégraphe. Il s'agissait de trouver un moyen efficient de communiquer et d'échanger de l'information. Pour cela, il a fallu mettre au point un codage, mais, suite à des différences culturelles par rapport au concept de caractère, il n'y a pas eu d'émergence d'un codage unifié.
Sur un ordinateur, l'unité de stockage de base est le bit. Ce dernier peut prendre deux valeurs différentes qui sont $0$ et $1$. En combinant des bits en séquences, on peut former des nombres binaires qui permettent notamment de représenter les nombres entiers. Une séquence de $n$ bits permet de représenter $2^n$ nombres binaires différents.
Au début, l'utilisation de séquences de $8$ bits, appelées octets, était habituelle et permettait de représenter $256$ nombres binaires différents permettant ainsi de représenter $256$ caractères différents, en attribuant un numéro à chaque caractère. La manière avec laquelle cette association est faite est définie par des normes de codage des caractères.
Encodage
Deux notions sont à distinguer lorsqu'il s'agit de définir une norme de codage de caractères. Un jeu de caractères (ou table de caractères) associe un nombre entier pour chaque caractère du jeu. L'encodage définit comment chacun de ces nombres entiers est encodé en une suite de bits ou d'octets, pour stockage ou transfert, par exemple.
ASCII
Au tout début est né l'ASCII (American Standard Code for Information Exchange) qui permet de représenter les caractères latins non accentués, défini par des américains pour l'anglais. La figure 2 montre les 128 caractères ASCII avec le nombre entier associé que l'on peut lire en hexadécimal en croisant le numéro de la ligne avec celui de la colonne correspondants au caractère voulu. Sept bits suffisent pour encoder tous ces caractères, même si l'on en utilise parfois huit par facilité, le huitième étant alors toujours fixé à zéro.

L'ASCII est évidemment insuffisant pour le reste du monde qui dispose de plus de caractères dans leurs alphabets respectifs. Chaque pays, et même chaque constructeur, a développé ses propres normes, ce qui a conduit à un grand désordre mondial.
La première solution consiste à doubler le nombre de caractères représentables, passant de $128$ à $256$, en exploitant le huitième bit non utilisé par l'ASCII. Plusieurs méthodes d'encodages peuvent être utilisées pour représenter les caractères des nouveaux jeux ainsi formés. La plus simple consiste à simplement stocker tous les caractères sur huit bits. On peut aussi construire des codages à longueur variable, utilisant plus ou moins de bits selon le caractère. La deuxième solution consiste à définir un nouveau jeu de caractères, universel, couvrant tous les systèmes d'écriture du monde entier.
ISO 8859
L'ISO (International Organization for Standardization) et la CEI (Commission Électrotechnique Internationale) ont proposé une norme commune de codage des caractères, l'ISO/CEI 8859, dont le but est d'exploiter le huitième bit non utilisé par l'ASCII, pour couvrir des symboles de l'alphabet latin non supporté par ce dernier. La philosophie principale de la norme est de se concentrer sur l'échange fiable d'information et non pas sur la typographie. Certains éléments, tels que des ligatures optionnelles, des guillemets incurvés, etc. ne sont donc pas présents. On notera, par exemple, que le « œ » utilisé en français (ligature phonétique) ou que le « fi » (ligature esthétique) ne sont pas présents, à la base.
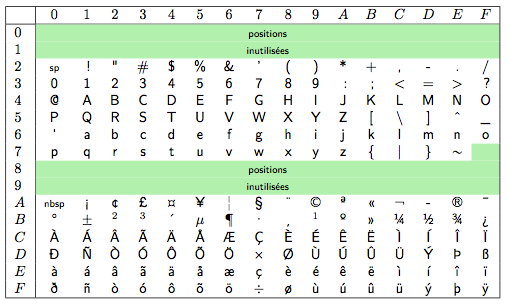
Étant donné le grand nombre de caractères non couverts par l'ASCII, dépassant les $128$ places complémentaires offerte par le huitième bit, plusieurs jeux de caractères ISO 8859-$n$ ont été définis. La plus largement utilisée, présentée à la figure 3, est l'ISO 8859-1 (ou latin-1) qui couvre la plupart des langues européennes occidentales. Cette dernière est aujourd'hui remplacée par l'ISO 8859-15 (ou latin-9), une révision qui abandonne les caractères les moins utilisés pour les remplacer par le symbole euro (€) et les lettres Š, š, Ž, ž, Œ, œ, et Ÿ, permettant ainsi une meilleure couverture du français, du finnois et de l'estonien.
Quoted-Printable
Quoted-Printable est un encodage, que l'on utilise notamment dans les e-mails, qui permet d'encoder des données sur huit bits en utilisant uniquement les caractères ASCII imprimables, encodables sur sept bits. L'idée, assez simple, est la suivante :
- Tous les caractères ASCII imprimables sauf le signe égal (de $33$ à $126$ sauf $61$), et les sauts de ligne, tabulations et espaces ($9$, $10$, $13$ et $32$) sont représentés tel quel.
- Les autres caractères sont représentés par un signe égal suivi de leur numéro exprimé en hexadécimal.
Par exemple, la chaine de caractères « Le caractère = n'est pas représentable tel quel. » sera encodée comme suit selon ISO 8859-1 :
Le caract=E8re =3D n'est pas repr=E9sentable tel quel.
On voit donc que trois caractères non ASCII ont été représenté par leur numéro dans le jeu ISO 8859-1 (E8 pour « è », 3D pour « = » et E9 pour « é ») et que tous les autres ont été encodés tel quel.
L'avantage de cet encodage est qu'il permet de préserver l'essentiel de la lisibilité du message, lorsque ce dernier n'est pas décodé. Point de vue stockage, un caractère occupera donc sept ou $3 \times 7 = 21$ bits, plutôt que de tous les stocker sur huit bits. Cela peut s'avérer intéressant si la plupart des caractères sont latins et non accentués.
Unicode
Enfin, Unicode est un standard récent dont le but est de permettre des échanges de textes au niveau mondial. Ce dernier se base sur la norme Universal Coded Character Set (UCS) de l'ISO/CEI 10646, qui définit un jeu de caractères équivalent. La version la plus récent d'Unicode a été publiée le 21 juin 2016, il s'agit d'Unicode 9.0. Elle comporte plus de 128000 caractères (la liste de tous les caractères Unicode peut être consultée sur le site web suivant : http://unicode-table.com/) couvrant des centaines de systèmes d'écriture aussi bien modernes qu'historiques. Son développement est géré par le consortium Unicode, dont le logo est repris à la figure 4, qui a pour but ultime de remplacer tous les encodages existants par les différents Unicode Transformation Format (UTF) proposés.
Les caractères Unicode peuvent être encodés de différentes manières. Le consortium Unicode propose d'utiliser UTF-8, UTF-16 ou UTF-32, où chaque caractère Unicode est encodé sur un certain nombre d'unités de base composées de $8$, $16$ ou $32$ bits.
L'encodage UTF-8 a été conçu pour être rétro-compatible avec l'ASCII, c'est-à-dire que les $128$ caractères de ce dernier sont encodés de la même manière avec UTF-8. Cet encodage est notamment le plus utilisé sur le web et est devenu, par ailleurs, l'encodage par défaut pour les documents HTML 5. Il nécessite entre un et quatre octets pour encoder les différents caractères de l'Unicode.
Python 3 utilise l'Unicode avec l'encodage UTF-8 pour gérer les chaines de caractères. De plus, les codes source des programmes Python doivent, par défaut, être écrits dans des fichiers encodés en UTF-8.