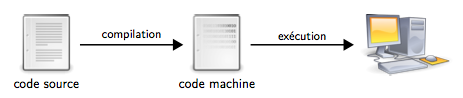
Chaine de compilation
Quelles sont les différentes étapes qu'il faut suivre à partir du moment où vous commencez par écrire un programme jusqu'au moment où vous pouvez l'exécuter sur votre ordinateur ?
- La première chose à faire est bien évidemment d'écrire le programme. On écrit le code source d'un programme en utilisant un langage de programmation (on utilise le langage C dans le cadre de ce livre). Un code source est un fichier texte, notamment lisible par un être humain.
- Une fois le code source écrit, il faut procéder à sa compilation. Cette étape part donc du code source pour produire un code machine. Un code machine est un fichier binaire, qui n'est pas lisible par un être humain (normalement constitué).
- Évidemment, une fois cela fait, il ne reste plus qu'à exécuter le code machine sur l'ordinateur qui est capable de comprendre ce code.
La figure 4 résume les différentes étapes de la chaine de compilation, depuis l'écriture du code source par le développeur jusqu'à l'exécution du code machine sur l'ordinateur.
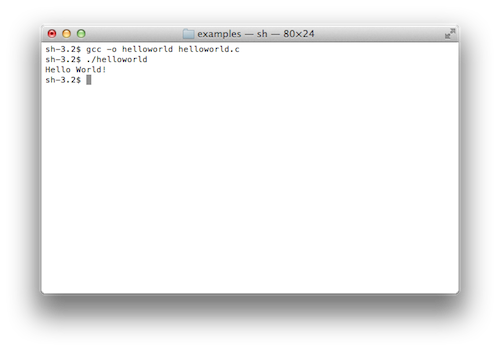
La figure 5 montre le résultat de la compilation du fichier helloworld.c qui produit un fichier exécutable appelé helloworld. Ce programme est ensuite exécuté et on peut voir que les mots « Hello World! » s'affichent bel et bien dans le terminal. Les détails de ces commandes sont décrites plus loin dans le livre.
helloworld.Préprocessing
L'étape de compilation, que l'on a décrite plus haut comme étant une seule étape, est en fait elle-même constituée de plusieurs étapes. Le code source subit d'abord un premier traitement appelé préprocessing avant la phase de compilation à proprement parler. La figure 6 montre les étapes détaillées de la chaine de compilation.
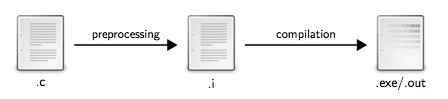
Le préprocessing prend le fichier source du programmeur comme entrée, fait subir une série de traitements à ce code source, et produit en sortir un nouveau code source. C'est ce nouveau code source qui est ensuite traduit en code machine par le compilateur. Le préprocesseur ne s'intéresse qu'à des instructions spéciales qui lui sont destinées, appelées directives préprocesseur. De plus, c'est également le préprocesseur qui est en charge de supprimer les commentaires. On va maintenant voir deux directives préprocesseur. La première permet d'inclure un fichier et la deuxième permet de définir des constantes. Il existe d'autres directives préprocesseur et on aura l'occasion d'en voir quelques autres plus loin dans ce livre.
Inclusion de fichier
La première directive permet d'inclure un fichier externe dans un autre fichier. La forme générale de cette directive est la suivante :
On utilise donc la directive #include suivie du nom du fichier à inclure, placé entre chevrons (<...>). Lorsqu'il rencontre une telle directive, le préprocesseur va charger le contenu du fichier externe, et le mettre à la place de la directive d'inclusion.
Si on reprend l'exemple du listing de la figure 3, et qu'on regarde le fichier helloworld.i généré par le préprocesseur, on peut voir que tout le contenu du fichier inclus stdio.h a été ajouté. Le fichier helloworld.i produit par le préprocesseur ressemble à ceci :
On voit donc clairement que la directive #include <stdio.h> a été remplacée par le contenu du fichier stdio.h. Dans ce fichier se retrouve notamment la déclaration de la fonction printf que vous pouvez voir; on tentera de comprendre cette déclaration plus loin dans ce livre.
Définition de constante
La seconde directive permet notamment de définir des constantes. Une constante est une valeur qui ne changera jamais, et que l'on veut identifier facilement grâce à un nom. On pense par exemple à la valeur de $\pi$ que l'on peut définir comme étant 3.14, ou alors au nombre de jours dans une semaine qui sera toujours égal à 7. La forme générale de cette directive est la suivante :
On utilise donc la directive #define suivie du nom de la constante et de la valeur de la constante. Ce que le préprocesseur va faire, c'est parcourir complètement le code source, et remplacer toutes les occurrences de NAME par value.
La figure 5 montre la transformation de code source qui est effectuée par le préprocesseur sur un petit programme d'exemple. Dans ce programme, on a définit une constante TEXT qui vaut "Hello World!\n", et qui sera donc remplacée partout dans le code source lors du préprocessing.
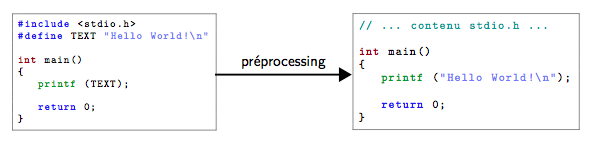
Comme on le verra en détails plus loin, définir des constantes est très utile notamment pour rendre le code plus lisible et pour faciliter son adaptation et sa maintenance.
Erreur de compilation
Lorsqu'on écrit un programme, on ne peut pas écrire n'importe quoi n'importe comment, il y a des règles à respecter. C'est la même chose lorsqu'on écrit un texte en français, il faut respecter les règles orthographiques et de grammaire. Évidemment, ces règles changent en fonction de la langue. Pour la programmation, c'est la même chose, il y a des règles à respecter, qu'on appelle les règles de syntaxe.
Ces règles sont vérifiées par le compilateur, et si vous avez écrit un code qui n'est pas valide, le compilateur va s'arrêter et produire une erreur de compilation. Prenons par exemple le programme suivant :
On peut voir facilement qu'on a oublié les guillemets pour délimiter le texte qui est à afficher par le programme. Si on tente de compiler ce programme, on se retrouve avec une erreur de compilation comme vous pouvez le voir ci-dessous :
compile-error.c:5:10: error: use of undeclared identifier 'Hello'
printf (Hello World!\n);
^
1 error generated.
Le compilateur s'est donc arrêté, et n'a pas produit le code machine. De plus, il essaie du mieux qu'il peut de vous indiquer la ligne (ou une ligne proche) de là où une erreur se situe. Voyons un autre exemple de code qui possède une erreur de syntaxe :
Comme vous l'aurez peut-être remarqué, il manque un point-virgule à la fin de l'avant dernière ligne. Le code n'est donc pas syntaxiquement correct et le compilateur génère une erreur comme vous pouvez voir ci-dessous :
compile-error.c:7:10: error: expected ';' after return statement
return 0
^
;
1 error generated.